HOWTO - Data Center Network Design
By Erik Rodriguez
This article provides information on network design and configuration of data center networks. Various technologies, protocols, and design methods are discussed.
Introduction
Data center network design is generally much different than corporate network design. Data centers have much more transport to/from the Internet than most corporate networks. There are different protocols and routing technologies at work in data centers. This article discusses common data center network configurations. Equipment, strategy, and deployment are discussed and illustrated.
Protocols
At the core level, data centers are running one or more forms of BGP. BGP is a common exterior routing protocol, but can be used as an interior gateway protocol in large networks. Smaller data center networks will rely on a simply form of interior routing protocols such as OSPF, or simply a long list of static routes.
Core Network
Core network functionality generally consists of exterior routing protocols (BGP) and directly connected networks from uplink providers and/or peering. Core devices come in many sizes (both physically and logically) and are obviously the most important part of network operation.
Top choices for core network gear include Cisco, Juniper, Brocade (formerly Foundry), Extreme Networks, and few others. Unlike distribution level gear, core routers have extremely fast backplanes that allow these devices to move large amounts of traffic with little to no latency. They also accept multiple power supplies, routing engines, and modular cards to accept different types of connections.
IP Address Allocation
Generally, each customer is assigned a specific VLAN with their IP allocation assigned an IP address. This serves as the customer's gateway and all other IP addresses will be usable by customer equipment. This is done for several reasons which are discussed in isolating VLANs for performance and security.
VLAN aggregation methodology
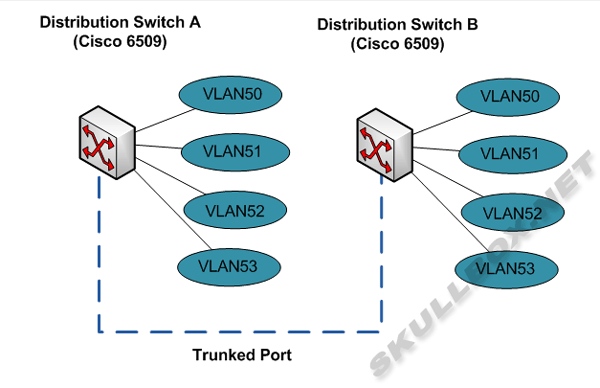
By traditional networking standards it makes sense to aggregate all VLANs in a core device. This allows traffic to transverse the core which different VLANs need to communicate. This is common in corporate networks, but can quickly lead to problems in a fast growing data center network. Providers that assign small IP allocations (in most cases /29s) can end up running low on VLANs in their aggregate devices. See the following illustration:
As you can see, there are two distribution routers each housing the same VLANs. Again, by traditional networking standards, it would make sense to have all your VLANs present across your network. This would increase the amount of layer 2 traffic within the network, and effectively use less CPU on your network gear. However, most dedicated server or colocation networks are sending the majority of traffic to the Internet. By aggregating the VLANs across multiple network devices, you create an effective layer 2 network path that each server will probably never use.
A simple analogy would be building a large metropolitan area with plenty of single lane roads and no freeways. Short trips within town should be quick, but if you need to get across a long stretch of town or leave completely, it would take much longer. This would all be due to a poor design that does not address effective means of travel outside the surrounding areas. The same concept applies to network design.
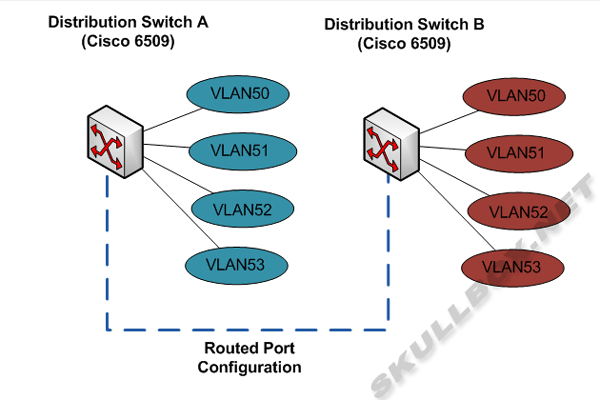
Knowing what we know now, the following design allows the re-use of VLAN numbers on different distribution switches. Traffic that needs to communicate internally can be routed to and from without using the same VLAN database across both switches. Most data centers eventually end up re-designing their networks at some point to move to the following design:
As you can see the common link between each distribution switch is now routed instead of being trunked. The trade off here is to have twice the amount of VLANs but switching the path between them from layer 2 to layer 3. This will use more CPU time on the network gear, but as I mentioned before, the devices attached to these switches will be communicating outside the data center network.
This design still allows external protocols like BGP to work as intended. Other connections such as dark fiber and peering connections will also still operate.
Equipment
Distribution switches which are commonly used in data center networks vary. Depending on the amount of bandwidth and total network capacity, the following are common candidates for distribution switches:
- Cisco 6500
- Cisco 4548
- Cisco 3750
The Cisco 6500 comes in various sizes from a 3U chassis to a 13U chassis. Modules such as 48 port gigabit line cards give providers the port density to make these customer facing devices. They can also run redundant power and supervisor cards. Other modules include multiple 10 Gbps line cards that can be attached to core routers or other distribution switches. The 6500 series can accommodate full routing tables for interior or exterior BGP.
This Cisco 4548 is 1U 48 port switches with dual 10 Gbps uplinks. They are high performance switches will a small footprint but are not as "full service" oriented as the 6500 series.
The Cisco 3750 is the smallest layer 3 switch that can accommodate small to medium amounts of traffic and also have dual 10 Gbps uplinks.
Other vendors have excellent solutions for distribution layers as well. Brocade and Juniper have excellent solutions, but they are not as commonly used. Some providers offering "budget" services will use lower-end and EOL switches like the Cisco 3550, 2950, and even 2900.
Contact Us
NOTE: this form DOES NOT e-mail this article, it sends feedback to the author.
|
|